亚马逊Alexa科学家:图灵测试70年已成古董,要给AI构建新的「黄金标准」了_详细解读_最新资讯_热点事件
![]() 63ke ·浏览 14 ·点赞 0 ·评论 0 ·3年前 (2021-01-06)
63ke ·浏览 14 ·点赞 0 ·评论 0 ·3年前 (2021-01-06)
编者按:本文来自微信公众号“新智元”(ID:AI_era),来源:unite.ai,编辑:小匀、yyan,36氪经授权发布。
1950 年,图灵提出著名的「图灵测试」去回答「机器能否思考」的问题,目的是判断机器是否能表现出人类也无法区分的对话行为。70年来,图灵测试也一直作为学术界的AI「北极星」而存在。近日,亚马逊语音助手 Alexa 部门的首席科学家认为,人们现在关心的是人机之间的互动,而不是区分机器和人类。他认为,图灵测试过时了,AI 需要新基准测试!
图灵测试可以退场了吗?
自从1950年艾伦·图灵发表论文回应「机器可以思考吗?」这一问题以来,已经过去70年。

图灵测试的目标,是确定机器是否能表现出人类无法区分的对话行为。在这个游戏中,谁是回应者,是人类还是人工智能,评估者是不被告知的。
在图灵的论文中,他本人也曾暗示过一个事实,即他认为图灵测试最终可能会被击败。他说:「到2000年,在一个模仿游戏中,一个普通人区分AI和人类的几率将低于70%,」
亚马逊语音助手 Alexa 部门的首席科学家罗希特·普拉萨德最近争辩说,长期用于衡量AI模型复杂程度的图灵测试,应该作为AI的基准而淘汰。

70年过去了,图灵测试该退场了吗?
旧基准与新时代:我们关心人机互动,不是区分机器和人类!
为了回答这个问题,让我们回到图灵第一次提出他的论文的时候。
1950年,第一台商用计算机还没卖出去;光缆的基础工作还要4年才能公布;人工智能领域也没有正式建立。
即使他的论文彻底改变了计算机科学和人工智能。但就在随后的2-4年里,图灵也因同性恋罪名而饱受折磨最后自杀。

幸运的是,他的「遗产」继续存在,而且在漫长的岁月里经受住了无数考验。
现在,人工智能已经发生了剧变。我们手机上的计算能力是阿波罗11号的10万倍,再加上云计算和高带宽连接,现在的AI可以在几秒钟内根据海量数据做出决策。
普拉萨德认为,图灵测试在很多方面是有局限性的,正如他手中的Alexa产品一样,很少会关心人类与AI的区别,而更关心与人工智能的密切互动。

例如,你要求你的AI助手关闭车库的灯,你并不希望与其对话。相反,你只希望它完成「确定」。
实际上,图灵自己甚至在他最初的论文中提到了这些当中的一些局限性。
普拉萨德认为,随着人工智能与人们生活方方面面的联系越来越紧密,图灵测试应该被认为是过时的,应被更有用的基准测试所取代。
此话不假,的确,许多早期的聊天机器人是为通过图灵测试而设计的,例如,类似「罗布能奖」 (The Loebner Prize) 和「话匣子挑战赛」 (The Chatterbox Challenge)的聊天机器人年赛,就是聚焦于图灵测试的。

但尽管如此,面对外界不断询问Alexa何时能够通过图灵测试时,普拉萨德指出,图灵测试仍然是聊天机器人和数字助理常用的基准。
他说,使用图灵测试评估机器智能性的其中一个主要问题是,它几乎完全削弱了机器查找信息和执行闪电般快速计算的能力。
比如说,装作停顿。
「3434756的立方根是什么?」
「西雅图到波士顿有多远?」
当听到这些问题时,人工智能程序完全能立即找到答案,但是,它们却会模仿人类的停顿。
除此之外,图灵测试没有考虑到人工智能使用外部传感器收集数据能力的日益增强,忽略了人工智能通过视觉和运动算法与周围世界进行交互的方式——只依赖于文本通信。

创建新的基准?
就像Alexa的功能一样,普拉萨德认为应该创造新的智能评估方式,适用于评估一般类型的智能机器。
这些测试应该能够搞清楚人工智能在多大程度上提高了人类的智力,以及人工智能在多大程度上改善了人们的日常生活。此外,测试应该弄明白人工智能是如何表现出类似人的智能特征的,包括语言能力、自我监督和「常识」。

当前人工智能研究重要的领域,如推理、公平性、对话和感官理解,并不是通过图灵测试来评估的,它们可以通过多种方式进行评估。
当时亚马逊创立Alexa 奖的标准是要求社交机器人与人类对话20分钟。这些机器人将被评估关于广泛话题连贯对话的能力,如科技、体育、政治和娱乐。顾客在机器人开发阶段对其打分,之后再次基于他们与机器人的聊天欲望对其进行打分。在最后一轮中,评委独立负责用五分制对机器人进行评分。评委们所使用的评价标准依赖于让人工智能在适当的情况下表现出移情等重要的人类属性的方法。
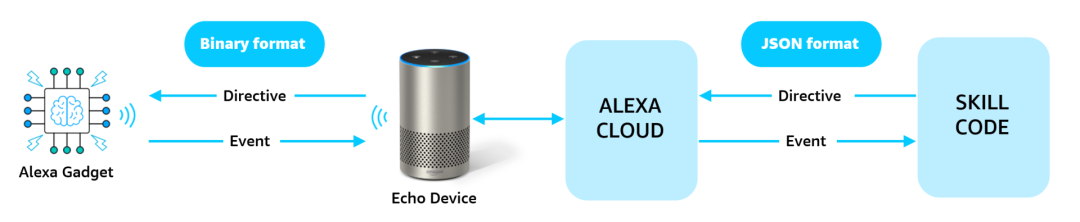
最终,普拉萨德认为像Alexa这样的人工智能装置的大量涌现,体现出衡量人工智能进程的重要机会,我们需要不同的策略来利用这个新机会。
普拉萨德解释到,人工智能若要成为处理大量任务方面的专家,只有具备更广泛的学习能力,而不是特定任务的智能,才有可能。因此,在未来十年乃至更长时间里,人工智能服务的实用性,以及它们在周围设备上的对话及主动协助能力是值得进行测试的。
图灵测试为何如此重要?
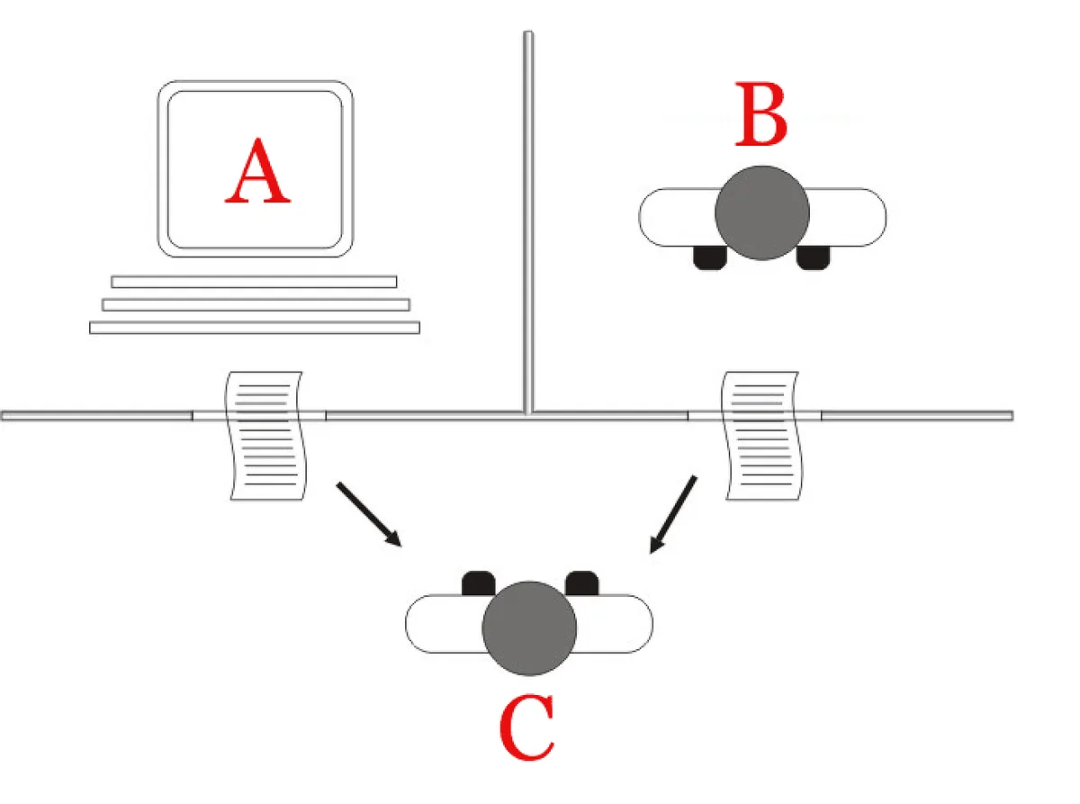
一个男人(A)女人(B),以及可能是两性的讯问者(C)。
游戏的概念是审讯者呆在与男人(A)和女人(B)都分开的房间里,目的是让审讯者识别男人是谁,女人是谁。在这种情况下,男人(A)的目的是欺骗询问者,而女人(B)可以试图帮助询问者(C)。为了公平起见,不能使用口头提示,而只能来回发送打字的问题和答案。问题就变成了:询问者如何知道该信任谁?
询问者仅通过标签X和Y知道它们,并且在游戏结束时,他只是简单地说「 X是A和Y是B」或「 X是B而Y是A」。
那么问题就变成了,如果我们把男人(A)或女人(B)去掉,把这个人换成一台智能机器,这台机器能不能用它的人工智能系统来欺骗审讯者(C),让他相信这是一个男人或一个女人呢?这就是图灵测试的本质。
换句话说,如果你在不知情的情况下与一个人工智能系统进行交流,而你又假设另一端的 「实体 」是一个人,那么人工智能能不能无限期地欺骗你呢?
图灵测试为何如此重要?
在图灵的论文中,他暗示了一个事实,即他认为图灵测试最终可能会被击败。他说:「到2000年,在一个模仿游戏中,一个普通人区分AI和人类的几率将低于70%,」
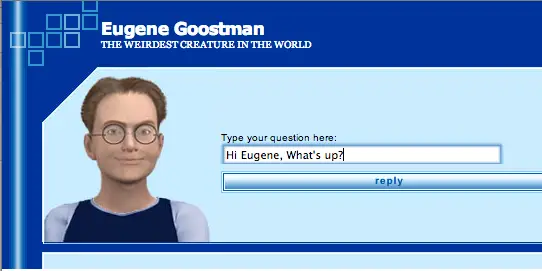
关于图灵测试被通过的报道很多。
2014年,一个名为Eugene Goostman的聊天机器人程序,模拟了一个13岁的乌克兰男孩,在一次图灵测试中,这个聊天机器人让伦敦皇家学会33%的评委相信它是人类。尽管如此,批评者很快就指出了测试的不足之处,时间太短!只有5分钟,这不足以来说明智能的程度。
2018年,在谷歌助手的协助下,谷歌Duplex预约系统假装成人类,给一家发廊打电话,同时与发廊的前台人员进行交流。短暂的交流后,「她」成功预约了一次理发。

然而,在这个自然语言处理(NLP)的时代,有自然语言理解(NLU)和自然语言解释(NLI)两个子领域,我们需要问一个问题,在不完全理解其背后的语境的情况下,这台机器是否真的智能?
毕竟,如果回顾一下IBM开发的Watson背后的技术,Watson是一个能够回答自然语言提出的问题的计算机系统,曾击败Jeopardy冠军,但Watson能够击败世界冠军,是通过互联网下载了一大批世界知识,包括维基百科在内的各种来源,却并不了解这种语言背后的背景。虽然,Watson在玩游戏的时候不能上网,但这对于一个人工智能来说,只是一个小小的限制,它只需要在游戏开始前获取人类所有的知识就可以了。

类似于搜索引擎,进行了关键词和参考点。如果一个人工智能能够达到这种理解水平,那么我们应该考虑到,基于今天不断进步的技术,欺骗一个人类5分钟或10分钟,根本没有设置足够高的门槛。
不断移动的门槛
正是由于对现代AI的需求在改变,我们应该重新考虑图灵测试的新的现代定义。
回顾人工智能的发展史,人工智能能否达到人类水平智能的最终晴雨表,几乎都是基于它是否能在各种游戏中击败人类。
1949年,克劳德-香农发表了关于如何让计算机下棋的想法,因为这被认为是人类智慧的终极巅峰。

1996年2月10日,经过3个小时的艰苦比赛,国际象棋世界冠军加里-卡斯帕罗夫(Garry Kasparov)在与IBM计算机 「深蓝」(Deep Blue)的六局比赛中输掉了第一局,「深蓝」每秒能评估2亿步棋。

快到2015年10月,AlphaGo与三届欧冠卫冕冠军樊麾先生进行了第一场比赛。AlphaGo以5比0的比分赢得了史上第一场与围棋职业选手的比赛。围棋被认为是世界上最复杂的棋局,它有10360种可能的棋步。

可以见得,争论的焦点是,在大型多人在线角色扮演游戏中,人工智能必须能够击败玩家团队。
但目前的测试可能过于依赖欺骗、聊天机器人中的技术。目前,在我们的实际世界中,人工智能将需要进行互动和 「生活」,而不是游戏环境或模拟环境及其定义的规则。
参考链接:
https://www.unite.ai/head-researcher-for-amazon-alexa-argues-turing-test-is-obsolete/




